
At its core Genkanban does two things: predicts your context and takes actions on the basis of the predicted context. When first installed, Genkanban does not “know” you and cannot predict your context until it is trained. There are two methods of training Genkanban, described below. In order for Genkanban to function, you must first spend some time training it.
All of the functionality described below is accessible from the Genkanban status menu represented by a bell in menu bar:
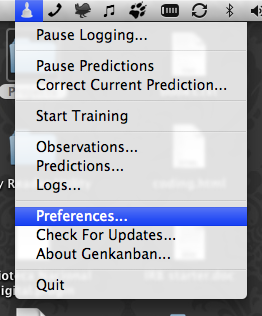
Training method 1: Uniform sampling
Using uniform sampling of your context, Genkanban collects context labels from you at regular intervals. This is the conceptual equivalent of someone asking you every five minutes, “Am I doing it right?”
To enable this training method, open the Preferences and select the Training tab. Within this tab, you can select a training interval ranging from thirty seconds to five minutes. This is how often Genkanban will interrupt you for new context labels. You may choose to enable an audible cue that sounds with the interruption. This sound is a small bell and may be useful if you work on a busy desktop where a small window my be lost among the others.
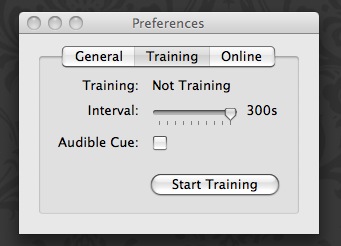
To begin training, click the “Start Training” button. The system will begin to interrupt you periodically until you stop the training. You may adjust the interval or toggle the audible cue without stopping and restarting the training process. In addition to the button within the preferences, training may be toggled using the “Start Training” menu item under the bell icon in your status bar. Restarting training does not begin the process anew – instead it simply continues from where it left off.
(Note that as of 1.0b3, there is no “reset training” functionality. You would like to start over, please post a comment below and I’ll provide instructions for resetting training. This functionality will be included in a future revision.)
Training method 2: Correct on error
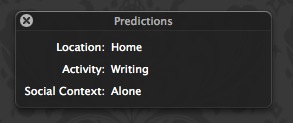
If you do not want to be interrupted periodically and would like to take responsibility for monitoring Genkanban’s training, you can use a simple “correct on error” approach to teaching Genkanban. To do this, select “Predictions…” from the bell menu in your status menu. This will bring up a translucent black heads-up display (HUD) that can be placed anywhere on your screen. This HUD displays the context Genkanban currently predicts:
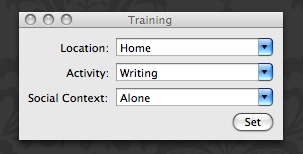
If you see that Genkanban is making an incorrect prediction, you can correct it by selecting “Correct Current Prediction…” from the bell status menu. This brings up the window used to train Genkanban and you can select an existing label or enter a new one. When you click the “Set” button, your current context and environment is sent to the machine learner and this generates a new prediction based on the new evidence.
The pros and cons of the different methods
The uniform sampling training method will collect more information about you as you use the computer throughout the day. You will not have to remember to give it new information, as it will periodically interrupt you for context labels.
The “correct on error” method eliminates the interruptions at the cost of you being responsible for verifying the predictions of the system. Ideally, this method only collects labels that contradicts the existing model, so the a wider variety of contexts should be predictable using a smaller number of samples.
Please note that these training methods are not mutually exclusive and can be intermixed as desired. You can correct the system’s current prediction while using the uniform sampling method. You my choose to begin using the uniform sampling method and then switch over to the “correct on error” method.
I personally prefer to use the “correct on error” method to avoid the regular interruptions. However, I do not know which method is the optimal one for building a more reliable model. This is an open research question that I plan to answer while building this system.
